
Data pipelines are a set of processes that move data from one place to another, often involving transformation and processing of the data along the way. There are several types of data pipelines, including
- Batch processing: Collecting and processing data in large chunks at regular intervals. It is typically used when the volume of data is high and the latency requirements are not very strict. Batch processing is suitable for scenarios where data can be processed offline, such as when it is not required in real-time.
- Stream processing: Continuously processing data as it is generated in real-time. It is typically used when the data is generated continuously and the latency requirements are strict, as the data must be processed as soon as it is generated. Stream processing is suitable for scenarios where data needs to be processed in real-time, such as when it is used to trigger an action or alert.
- Micro-batching (batch + stream processing): It is a hybrid approach that involves processing data in small batches at high frequency. It combines the benefits of batch processing (such as the ability to process large volumes of data) with the benefits of stream processing (such as low latency). Micro-batching is suitable for scenarios where the volume of data is high and the latency requirements are strict, but not as strict as in stream processing.
These patterns can be implemented using a variety of tools and technologies, such as Apache Hadoop, Apache Spark, and Apache Flink. Cloud services such as AWS, Azure, and Google Cloud offer a range of tools and services that can be used to implement these patterns in a scalable and cost-effective manner.
The main components of a data pipeline include the
- data source (upstream)
- the destination or sink (downstream)
- the transformations and business logic applied to the data
Type of data processing pipeline
Data transformation is the process of converting data from one format or structure to another, often for the purpose of making it more suitable for analysis or integration with other systems. There are several different patterns for performing data transformation, including Extract Load (EL), Extract Transform Load (ETL), Extract Load Transform (ELT), and Extract Transform Load Transform (ETLT). Each of these patterns has its own benefits and drawbacks, and is better suited to certain scenarios than others.
Extract Load (EL)
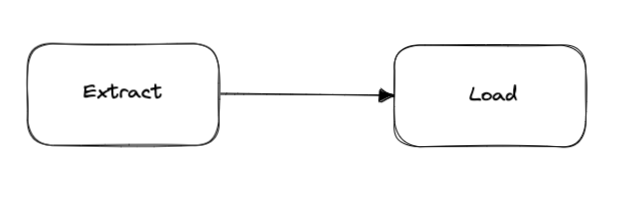
The Extract Load (EL) pattern involves extracting data from one or more sources, and then loading it into a destination system without any transformation. This pattern is often used when the source data is already in a suitable format for the destination system, or when the data does not need to be transformed for any other reason.
Scenarios:
EL is often used when the source and destination systems have similar data structures, or when the data does not need to be modified in any way.
Pros:
- Simplicity: EL is a simple and straightforward pattern that does not require any transformation logic to be implemented.
- Speed: EL can be faster than other patterns because it does not involve any transformation processing.
Cons:
- Limited flexibility: EL does not allow for any data transformation, so it may not be suitable for scenarios where data needs to be modified or cleansed before being loaded into the destination system.
Extract Transform Load (ETL)
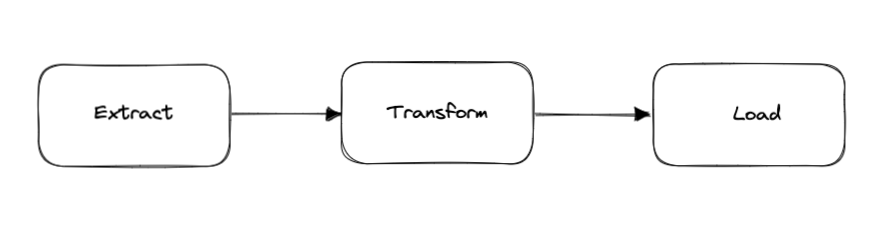
The Extract Transform Load (ETL) pattern involves extracting data from one or more sources, transforming it in some way, and then loading it into a destination system. This pattern is commonly used to cleanse, enrich, or otherwise modify data before it is loaded into the destination system.
Scenarios:
ETL is often used when the source and destination systems have different data structures, or when the data needs to be modified in some way before being loaded into the destination system.
Pros:
- Flexibility: ETL allows for a wide range of data transformation logic to be implemented, making it suitable for a variety of scenarios.
- Data cleansing: ETL can be used to cleanse data by removing errors, inconsistencies, or other issues that may impact the accuracy or quality of the data.
Cons:
- Complexity: ETL requires the implementation of transformation logic, which can be complex and time-consuming.
- Performance: ETL can be slower than other patterns due to the transformation processing required.
Implementation on cloud services:
To implement an ETL pipeline on
- Google Cloud,
- Using Cloud Dataproc: Cloud Dataproc is a fully managed cloud service for running Apache Spark and Apache Hadoop clusters. You can use Cloud Dataproc to extract data from various sources, transform the data using Spark, and then load the transformed data into a destination such as Cloud BigQuery or Cloud Storage.
- Using Cloud Composer: Cloud Composer is a fully managed workflow orchestration service that lets you schedule and automate the execution of tasks using Apache Airflow. You can use Cloud Composer to create an ETL pipeline by defining tasks for extracting data from various sources, transforming the data, and loading the data into a destination.
- Using Cloud Functions: Cloud Functions is a fully managed serverless compute platform that lets you run code in response to events. You can use Cloud Functions to build an ETL pipeline by creating functions that are triggered by events such as a new file being added to Cloud Storage or a new row being added to a Cloud BigQuery table.
- Using Cloud Data Fusion: Cloud Data Fusion is a fully managed, cloud-native data integration platform that allows you to create, schedule, and orchestrate data pipelines using a visual interface. You can use Cloud Data Fusion to extract data from various sources, transform the data using a variety of built-in transformations, and load the transformed data into a destination such as Cloud BigQuery or Cloud Storage.
- Azure, you can use the Azure Data Factory service to implement an ETL pipeline by creating a pipeline that extracts data from a source system, transforms it using custom logic, and loads it into a destination system. You can also use the Azure Functions service to create custom logic for data transformation.
- AWS, you can use the AWS Glue service to implement an ETL pipeline by creating a job that extracts data from a source system, transforms it using custom logic, and loads it into a destination system. You can also use the AWS Lambda service to create custom logic for data transformation.
Extract Load Transform (ELT)
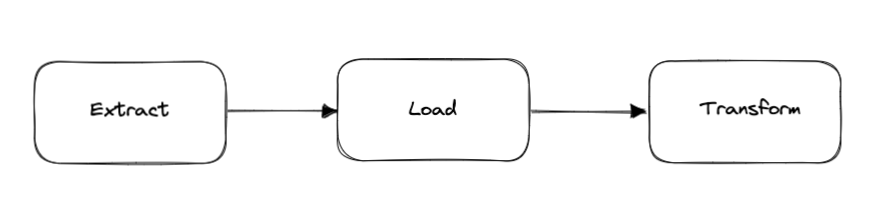
The Extract Load Transform (ELT) pattern is similar to ETL, but the data transformation step is performed after the data has been loaded into the destination system. This pattern is often used when the destination system is better equipped to handle data transformation than the source system.
Scenarios:
ELT is often used when the source system is not powerful enough to handle the transformation processing, or when the destination system is better equipped to perform the transformation.
Pros:
- Performance: ELT can be faster than ETL because the transformation step is performed after the data has been loaded into the destination system.
- Scalability: ELT can be more scalable than ETL because the transformation step is performed on the destination system, which may be more powerful and better able to handle large volumes of data.
Cons:
- Limited transformation options: ELT is limited in the types of transformations that can be performed, as the transformation step is performed on the destination system, which may not have the same capabilities as the source system.
Implementation on cloud services:
ELT can be implemented using tools such as AWS Redshift or Azure Synapse, which allow data to be loaded into a powerful data warehouse and then transformed using SQL or other languages supported by the destination system.
Extract Transform Load Transform (ETLT)
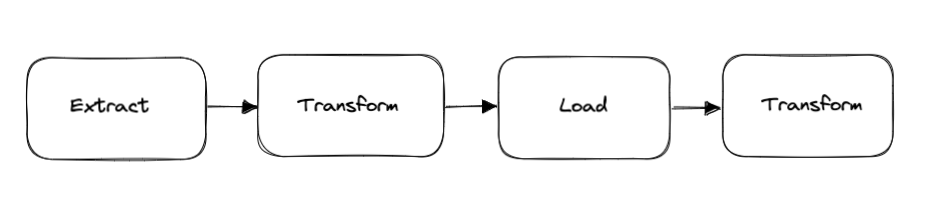
The Extract Transform Load Transform (ETLT) pattern involves extracting data from one or more sources, transforming it in some way, loading it into a destination system, and then transforming it again. This pattern is often used when the data needs to be transformed multiple times, or when the destination system requires a specific format that cannot be achieved through a single transformation step.
Scenarios:
ETLT is often used when the data needs to be transformed multiple times, or when the destination system requires a specific format that cannot be achieved through a single transformation step.
Pros:
- Flexibility: ETLT allows for multiple transformation steps to be performed, making it suitable for scenarios where the data needs to be modified in a complex or customized way.
Cons:
- Complexity: ETLT requires multiple transformation steps to be implemented, which can be complex and time-consuming.
- Performance: ETLT can be slower than other patterns due to the multiple transformation steps required.
Implementation on cloud services:
ETLT can be implemented using tools such as AWS Glue or Azure Data Factory, which allow data to be extracted from a variety of sources, transformed using custom logic, loaded into a destination system, and then transformed again using additional logic.
In conclusion, there are several different patterns for performing data transformation, each with its own benefits and drawbacks. The appropriate pattern will depend on the specific requirements and constraints of the data transformation scenario. Cloud services such as AWS, Azure, and Google Cloud offer a range of tools and services that can be used to implement these patterns in a scalable and cost-effective manner.





{kind=link}