
Welcome to the intricate world of Apache Spark, where the vast potential for data processing comes hand in hand with the challenges of debugging and optimization. In this narrative, let’s explore the common pitfalls in Spark and how to gracefully navigate through them, enhancing both our understanding and our applications.
The Two Faces of Error: Code and Data
When working with Spark, the first step in our debugging journey is recognizing that errors generally fall into two broad categories: code errors and data errors.
Code Errors
Syntax Error
Syntax errors are caused by incorrect arrangement or use of code syntax. In Spark, this often relates to incorrect DataFrame transformations or SQL query formatting.
Here’s a summary of common syntax errors in Spark:
- Misplaced or missing characters in code, like parentheses, quotes, or commas.
- Incorrect order of function arguments.
- Typo in DataFrame transformations or SQL query keywords.
- Using functions or methods that don’t exist in the PySpark AP
Imagine you’re crafting a complex Spark query. Suddenly, you’re confronted with a syntax error. These are often the low-hanging fruit of programming bugs, stemming from simple typos or a lapse in remembering the correct format. Think of it like a grammatical error in a sentence; it disrupts the flow. For instance, a missing quotation mark or a misplaced parenthesis can send your Spark job into a spiral of confusion.
Spark Code Example:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("SyntaxErrorExample").getOrCreate()
# Incorrect syntax: Missing closing quote
df = spark.createDataFrame([(1, "Alice"), (2, "Bob")], ["id", "name"])
df.select("name).show() # Syntax error
Attribute errors
Attribute errors occur when you reference an attribute or method that doesn’t exist for a particular object in Spark, such as a DataFrame or Column.
Here’s a summary of common attribute errors in Spark:
- Calling a method on an object that doesn’t support it (e.g., invoking DataFrame methods on a Column object).
- Mistyping the name of a method or property of DataFrame, Column, or other Spark objects.
- Attempting to access a DataFrame column incorrectly (e.g.,
df.column_nameinstead ofdf["column_name"]).
These are a bit sneakier, often a result of calling upon a method or attribute that simply doesn’t exist in the context you’re using it. It’s like asking a cat to bark - no matter how politely you ask, it’s just not equipped to do so. In Spark, this might mean you’ve tried to invoke a DataFrame operation on a column object.
Spark Code Example:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("AttributeErrorExample").getOrCreate()
df = spark.createDataFrame([(1, "Alice"), (2, "Bob")], ["id", "name"])
# Incorrect: 'Column' object has no attribute 'Select' should be 'select'
df = df.Select(df.name.toUpperCase()) # AttributeError
Analysis Exceptions
Analysis Exceptions occur at a higher level in Spark. They’re typically thrown during the analysis phase of a Spark SQL query or DataFrame transformation, often due to issues in the logical plan of the query. This might involve referencing a column that doesn’t exist, using functions incorrectly, or trying to perform operations on incompatible data types.
Here’s a summary of common Analysis Exceptions in Spark:
- Referencing a column that doesn’t exist in the DataFrame.
- Logical errors in SQL queries, such as incorrect JOIN conditions.
- Misuse of Spark SQL functions or incorrect function parameters.
- Schema mismatch in DataFrame operations, such as joining DataFrames with incompatible schemas.
Think of Analysis Exceptions as misunderstandings between what you’ve instructed Spark to do and what Spark thinks is possible given the structure and schema of your data. It’s like asking someone to fetch a book from a shelf that doesn’t exist in the library.
Spark Code Example:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("AnalysisExceptionExample").getOrCreate()
df = spark.createDataFrame([(1, "Alice"), (2, "Bob")], ["id", "name"])
# Incorrect: 'age' column doesn't exist
df.select("age").show() # Analysis Exception
Py4J Java Errors
Py4J Java errors, on the other hand, are a bit more general and can be trickier to diagnose. They stem from the interaction between PySpark (the Python API for Spark) and the underlying Java Virtual Machine (JVM) that runs Spark. These errors can be caused by a variety of issues, including but not limited to, problems with the Spark configuration, resource allocation issues, or even bugs within Spark itself.
Here’s a summary of common Py4J Java errors in Spark:
- Issues with Spark configuration settings (e.g., setting invalid memory or core limits).
- Incorrect use of Spark context or Spark session.
- Errors stemming from the underlying JVM that might be related to resource allocation, serialization, or task execution.
- Interaction issues between PySpark and the Java Virtual Machine, especially when using UDFs (User Defined Functions) or custom libraries.
These errors are akin to having a conversation in two different languages without a proper translator. There’s a disconnect between what your Python code intends and how the JVM interprets or executes that intention.
These errors, while frustrating, are often simple to fix once identified. A careful review of your code, keeping an eye out for these common slip-ups, can save you hours of head-scratching.
Spark Code Example:
from pyspark.sql import SparkSession
# Incorrect configuration: Setting an invalid value for a Spark configuration
# This might lead to a Py4J Java error as it disrupts the JVM setup
spark = SparkSession.builder.appName("Py4JJavaErrorExample").config("spark.executor.memory", "invalid-value").getOrCreate()
df = spark.createDataFrame([(1, "Alice"), (2, "Bob")], ["id", "name"])
df.show()
Data Errors: When Data Doesn’t Play Nice
Moving onto data errors, the scenario gets a bit more complex. You might face issues like processing a small sample of data seamlessly, but when you scale up to the full dataset, things fall apart. This could be due to unforeseen null values, different data types, or even corrupt data lurking in your dataset, like a needle in a haystack.
Here are some common types of data errors you might encounter in Spark:
- Missing Data:
- Occurs when there are null or nonexistent values in your dataset.
- Can lead to unexpected behavior or errors in calculations and transformations.
- Corrupt Data:
- Involves data that is malformed or in an unexpected format.
- Common in scenarios where data is ingested from uncleaned or diverse sources.
- Inconsistent Data Types:
- Occurs when data of different types is found in the same column (e.g., a mix of strings and integers).
- Can cause errors or unexpected behavior in data processing and aggregations.
- Skewed Data:
- Refers to an uneven distribution of data across your Spark partitions.
- Can lead to performance bottlenecks, as some tasks may have much more work to do than others.
- Duplicate Data:
- Involves having repeated rows in your dataset.
- Can lead to incorrect calculations, especially in aggregations and statistical analyses.
- Outliers:
- Extreme values that differ significantly from most of the data.
- Can skew results and may need special handling or cleaning.
- Scale Issues:
- Occurs when the data size is either too small to represent an accurate sample or too large to be processed efficiently.
- Can cause errors or inefficiencies in processing.
The key to tackling these data demons is a robust understanding of your dataset. Implement checks for null values, ensure consistent data types, and be prepared for anomalies. Handling corrupt data, for instance, requires a keen eye to identify and cleanse or bypass these troublesome records.
The Art of Debugging: Identifying and Fixing Errors
With a clear understanding of the types of errors, the next step is mastering the art of debugging in Spark’s distributed environment. This is where the detective work comes in.
The provided diagram is a clear and well-structured visual representation of the debugging process in Apache Spark.
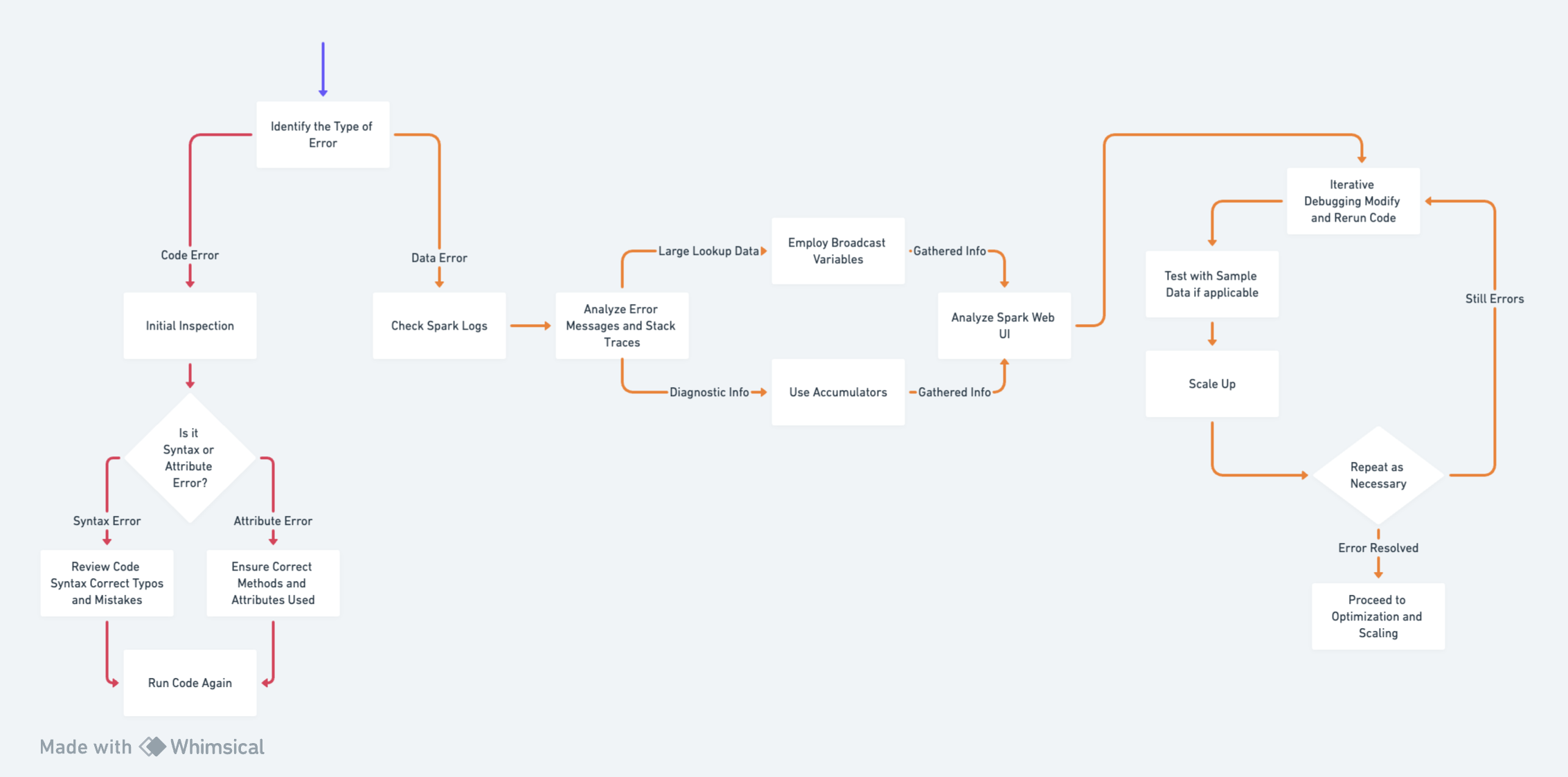
Below are the steps to follow when debugging your Spark application:
- Identify the Type of Error
- Is it a Code Error (Syntax, Attribute) or a Data Error (Data-related issues)?
- Initial Inspection
- Review your code for obvious mistakes (typos, incorrect method calls, etc.)
- Check Spark Logs
- Examine the executor and driver logs for error messages and stack traces.
- Useful for both Code and Data Errors.
- Use Accumulators for Diagnostic Info
- If dealing with data errors or complex logical issues:
- Implement accumulators to count occurrences of specific conditions.
- Example: Counting null values or invalid entries across partitions.
- If dealing with data errors or complex logical issues:
- Employ Broadcast Variables for Large Lookup Data
- If the error might be related to inefficient data distribution:
- Use broadcast variables to share large, read-only lookup data efficiently.
- If the error might be related to inefficient data distribution:
- Analyze Spark Web UI
- Access
http://<driver-node>:4040to view job details. - Check DAG visualization, task execution times, and shuffle details.
- Access
- Iterative Debugging
- Modify your code based on insights from logs and Spark UI.
- Rerun and observe changes in behavior or error messages.
- Test with Sample Data (if applicable)
- If errors are data-specific, test your logic with a controlled sample dataset.
- Scale Up
- Once the error is resolved on a smaller dataset, gradually scale up to the full dataset.
- Repeat as Necessary
- Debugging is often an iterative process, especially in distributed environments.
Remember, in Spark, printing statements might not always work as expected due to the distributed nature of the computations. Instead, rely on these more sophisticated tools to gather the clues you need.
Accumulators and broadcast variables become your magnifying glass and flashlight, helping you aggregate information across the cluster and distribute large values efficiently. Then there’s the Spark Web UI, akin to your high-tech detective dashboard, where you can monitor job executions, inspect DAGs, and get a bird’s-eye view of your tasks.
Beyond Debugging: Code Optimization
Once your code is error-free, it’s time to put on your optimization hat. Spark, with its immense capabilities, also offers ample room for tuning your applications for better performance.
Understanding Data Skewness
Data skewness in Spark refers to uneven distribution of data across partitions. This can lead to certain tasks taking much longer to complete than others, causing inefficiencies.
It’s like having one worker do all the heavy lifting while others stand idle. By understanding and addressing data skewness, you can ensure a more balanced workload distribution. This can be achieved by,
-
Use Alternate Columns for Partitioning
When the default partitioning results in data skew, consider using a different column that has a more uniform distribution.
Suppose you have a DataFrame
sales_dfwith a highly skewedregion_idcolumn. Instead, you might use a more evenly distributedproduct_idfor partitioning.# Repartitioning using a column with more uniform distribution sales_df = sales_df.repartition("product_id") -
Make Composite Keys
Creating composite keys means combining multiple columns to form a unique key for each row. This can help distribute data more evenly.
Imagine a DataFrame
transactions_dfwith columnsuser_idandtransaction_date. A composite key can be formed for better distribution.from pyspark.sql import functions as F # Creating a composite key transactions_df = transactions_df.withColumn("composite_key", F.concat_ws("_", "user_id", "transaction_date")) transactions_df = transactions_df.repartition("composite_key") -
Partition by Number of Spark Workers
Optimally, the number of data partitions should match the number of available Spark workers to utilize the cluster resources effectively.
If your cluster has 10 workers, you might repartition your DataFrame accordingly.
num_workers = 10 data_df = data_df.repartition(num_workers)
Inefficient Resource Allocation
Inefficient resource allocation occurs when the resources (like memory and CPU cores) assigned to Spark tasks are not optimal, leading to either underutilization or bottlenecks.
Configuring the number of executors, cores, and memory can be done through Spark’s configuration settings. For instance, you might set the number of executors to 10, each with 2 cores and 4GB of memory.
from pyspark.sql import SparkSession
# Building a Spark Session with specific configurations
spark = SparkSession.builder \
.appName("Optimized App") \
.config("spark.executor.memory", "4g") \
.config("spark.executor.cores", "2") \
.config("spark.executor.instances", "5") \
.getOrCreate()
Inefficient Resource Allocation
Fine-tuning your Spark SQL queries, avoiding unnecessary shuffles, and intelligently caching data can transform your Spark application from a lumbering giant into a nimble gazelle.
Avoiding Shuffles
Shuffles are expensive operations in Spark that occur during wide transformations like groupBy and join. They involve redistributing data across different nodes and can significantly slow down processing.
Consider a DataFrame sales_df where you want to calculate total sales per region. Using groupBy will cause a shuffle. To optimize, you might cache the DataFrame if it’s used multiple times.
sales_df.cache() # Caching for repeated use
total_sales_per_region = sales_df.groupBy("region_id").sum("sales")
Using Broadcast Joins
When joining a large DataFrame with a small one, broadcasting the smaller DataFrame can optimize the join operation. This sends a copy of the small DataFrame to each node, preventing a costly shuffle of the large DataFrame.
Joining a large transactions_df DataFrame with a small lookup_df DataFrame.
from pyspark.sql.functions import broadcast
# Broadcasting the smaller DataFrame
optimized_join_df = transactions_df.join(broadcast(lookup_df), transactions_df.user_id == lookup_df.id)
Caching Intermediate Results
Caching intermediate results in Spark can greatly improve performance, especially when the same data is accessed multiple times in subsequent transformations.
Suppose you have a multi-step transformation process on a DataFrame data_df.
# Caching intermediate DataFrame
intermediate_df = data_df.filter(data_df.value > 100).cache()
# Performing further transformations
result_df = intermediate_df.groupBy("category").count()
Conclusion: The Journey Continues
The journey of mastering Spark is both challenging and rewarding. As you navigate through the complexities of debugging and optimization, remember that each error, each roadblock, is an opportunity to deepen your understanding and enhance your skills. With patience, practice, and a keen eye for details, the world of Spark becomes not just manageable, but truly exhilarating.




{kind=link}