
Welcome back to my series on understanding the intricacies of Natural Language Processing (NLP) and its applications in data science and large language models. If you’ve been following along, you’ll recall that in our first blog post in this series, we dove into the world of NLP and explored the concept of embeddings. In the second blog of this series, we expanded our discussion to language modeling, touching on techniques like Word2Vec and Recurrent Neural Networks (RNNs).
Today, we’re delving into the transformative world of transformers, the current state-of-the-art in language modeling.
Transformers have revolutionized the way machines understand language by addressing a critical issue inherent in previous models: unidirectionality.
Traditional language models would only consider context from one direction, either from the left or the right of a given word in a sentence.
Take the sentence “The cat chased ___.” for example. Older models would only use the information that comes before the blank, “The cat chased “ to predict the next word. They wouldn’t take into account any words that might come after the blank to influence their prediction.
Transformers, however, look at both sides, understanding context from the left and the right, providing a more holistic understanding of language.
How Transformer works ?
To break it down, let’s consider the same sentence: “The cat chased ___.” Instead of guessing words like “dog” or “mouse” based solely on the preceding words, a transformer uses what’s known as the MASK token to fill in the gap.
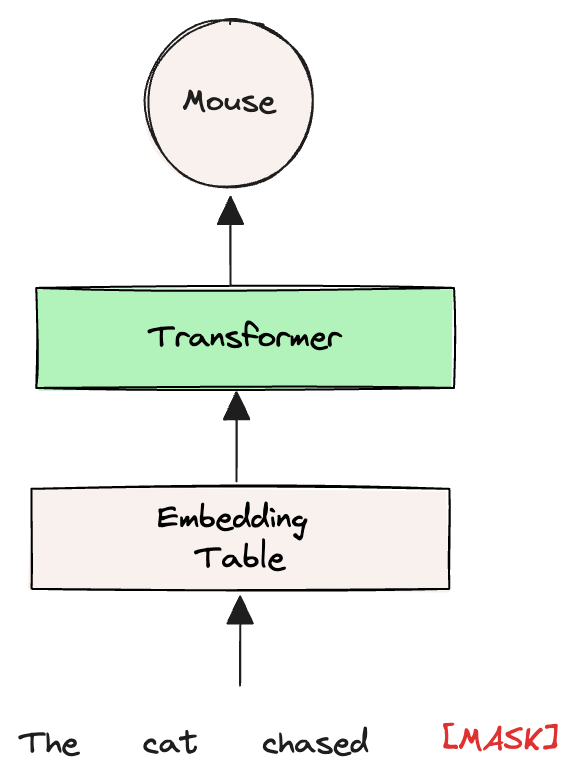
This MASK is a special placeholder that tells the model, “Hey, there’s a word missing here, figure out what it could be by considering the entire sentence.”
Now, here’s how it works: each word in the sentence, including our MASK token, is converted into an embedding — think of these as numerical representations that capture the essence of each word. These initial embeddings might be something we’re already familiar with, like Word2Vec vectors.
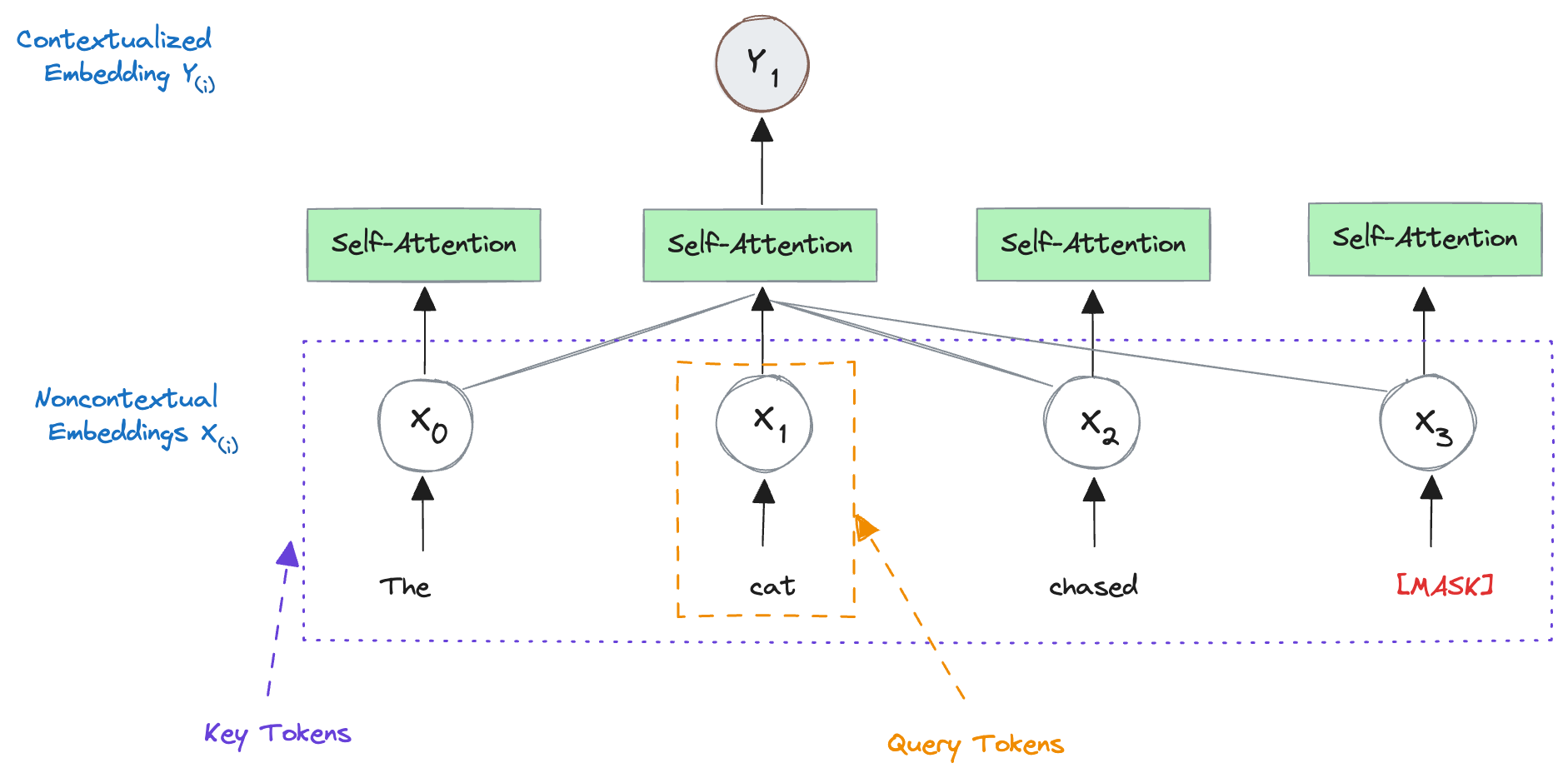
The magic happens in a process called self-attention, a key component of transformers.
In self-attention, each word (or its embedding) is given the opportunity to ‘interact’ with every other word in the sentence. So, our word “Cat” isn’t just looking back at “The” but is also considering what’s ahead, “chased” and the MASK token. Through this interaction, the model learns which words are most relevant to each other in a given context.
Imagine this like a group discussion where everyone listens to each other before contributing; that’s what self-attention achieves. It creates a dynamic where every word is influenced by every other word, leading to a rich, interconnected understanding of the sentence as a whole.
In transformer lingo, when we focus on
- “cat,” it’s known as the query token.
- The words around it, like “The,” “chased,” “MASK” become the key tokens. These key tokens help the model decide how much attention to pay to each word in relation to our query token.
You might wonder why we call them ‘query’ and ‘key’ tokens. Think of it like a dictionary search. In a regular dictionary, you look up a word (the query) to find its definition (the value). In the context of transformers, when we look up “cat” in a sentence like “The cat chased mouse on the road,” the word “cat” becomes the query. But instead of finding one definition, we’re interested in understanding “cat” with the help of all the other words, which are like keys in this analogy. Each key word is weighted differently based on its relevance to “cat”.
In our example, “Chased” is highly relevant to understanding “cat” in this context, so it would be given a higher weight. The word “the,” while less relevant, still gets a small weight. This weighting process allows the transformer to grasp the nuanced meaning of “Chased” in a way that’s specific to the context of the sentence.
Similarly, the query parameters transform the query token into a new vector. The better these transformations, the more accurately our transformer model can understand and predict language.
What is inside self-attention?
Now, let’s get technical for a moment and open up this “self-attention” box to see what’s inside. Within a transformer, there are three core components: key, query, and value parameters. These are matrices that transform the respective tokens. Please have a look at the below image
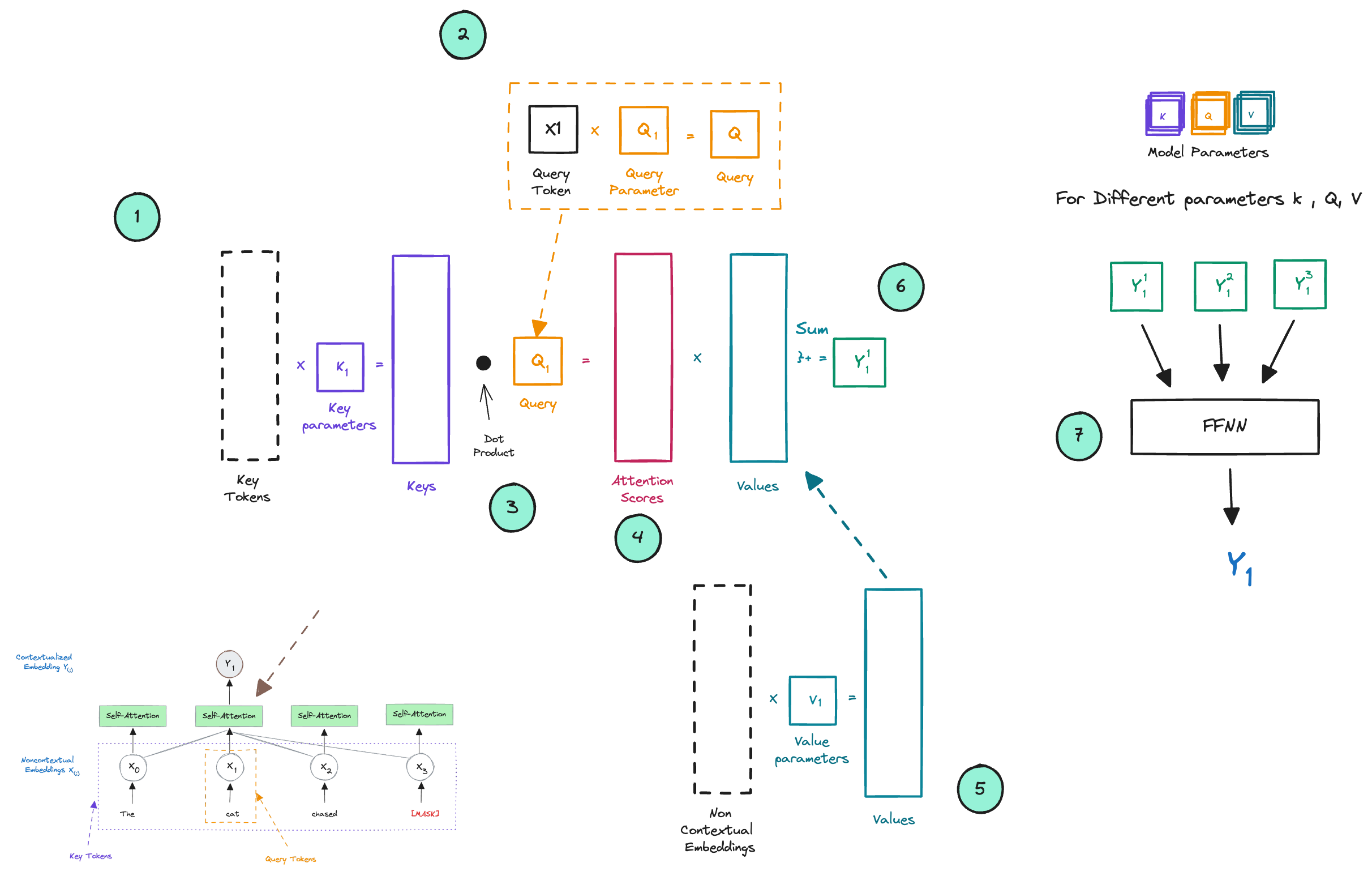
- Key Vectors: The input tokens (Non Contextual embeddings) are multiplied by the key parameters (matrix K) to produce key vectors. These key vectors represent the aspects of the tokens that will be used to determine the attention each token should pay to every other token.
- Query Vectors: Similarly, the input tokens are also multiplied by the query parameters (matrix Q) to produce query vectors. These vectors are used to query how much attention needs to be given to other tokens.
- Dot Product: For each token, its query vector is used to perform a dot product with all key vectors to compute a set of scores. These scores represent the compatibility between the tokens - essentially, how much focus a token should have on every other token.
- Attention Scores: The raw scores from the dot product are typically scaled down (e.g., divided by the square root of the dimension of key vectors) and then passed through a softmax function, which converts them into probabilities between 0 and 1. These are the attention scores.
- Value Parameters: Parallel to the above, input tokens are also multiplied by the value parameters (matrix V) to produce value vectors. The value vectors contain the information from the tokens that will be exchanged based on the attention scores.
- Weighted Values: The attention scores are used to weight the value vectors. This weighted sum gives you a new set of vectors, each a combination of values from all tokens weighted by how much each token should attend to every other token.
- Output and Feed-Forward Network (FFNN): The new vectors from each set of attention scores and value vectors are combined to produce the final output of the self-attention mechanism for each token. This process is carried out multiple times in parallel with different sets of key, query, and value parameters, creating what are known as attention heads. Each head focuses on different aspects of the information, allowing the model to pay attention to different positional and semantic features of the input data. The outputs from all heads are then concatenated and linearly transformed to maintain the original dimensionality, which is then passed through a feed-forward neural network (FFNN) to produce the final output Y.
The reasoning for multi-head attention is to enable the model to capture a richer representation of the data. Since each head can potentially learn to attend to different parts of the sequence in different ways, multi-head attention allows the model to consider various perspectives simultaneously, enhancing its ability to understand complex relationships and nuances in the data.
The Mechanics of Self-Attention
To set the stage, imagine a troupe of actors, all playing their parts but also attentively observing each other to deliver a performance that’s cohesive and dynamic. This is akin to the self-attention mechanism in transformers where each word (‘actor’) in a sentence not only plays its role but is also aware of the other words around it.
Although the term “self-attention” might sound complex, it’s simply a function that allows each word in our sentence to look at and derive context from the other words. When we say that “The cat chased the mouse,” the word “chased” is influenced by “cat” and “mouse,” but not by irrelevant words like “tree” or “the.”
In technical terms, this attention to every other token creates an O(N^2) complexity, which sounds expensive, and it is. But thanks to the parallel nature of transformers, this process is more like a team working simultaneously rather than a single worker doing one task at a time.
Transformers: A Stack of Self-Attention Layers
A transformer is essentially a stack of these self-attention layers, each with its own parameters, working together like a multi-level building where each floor contributes to the understanding of the language’s structure.
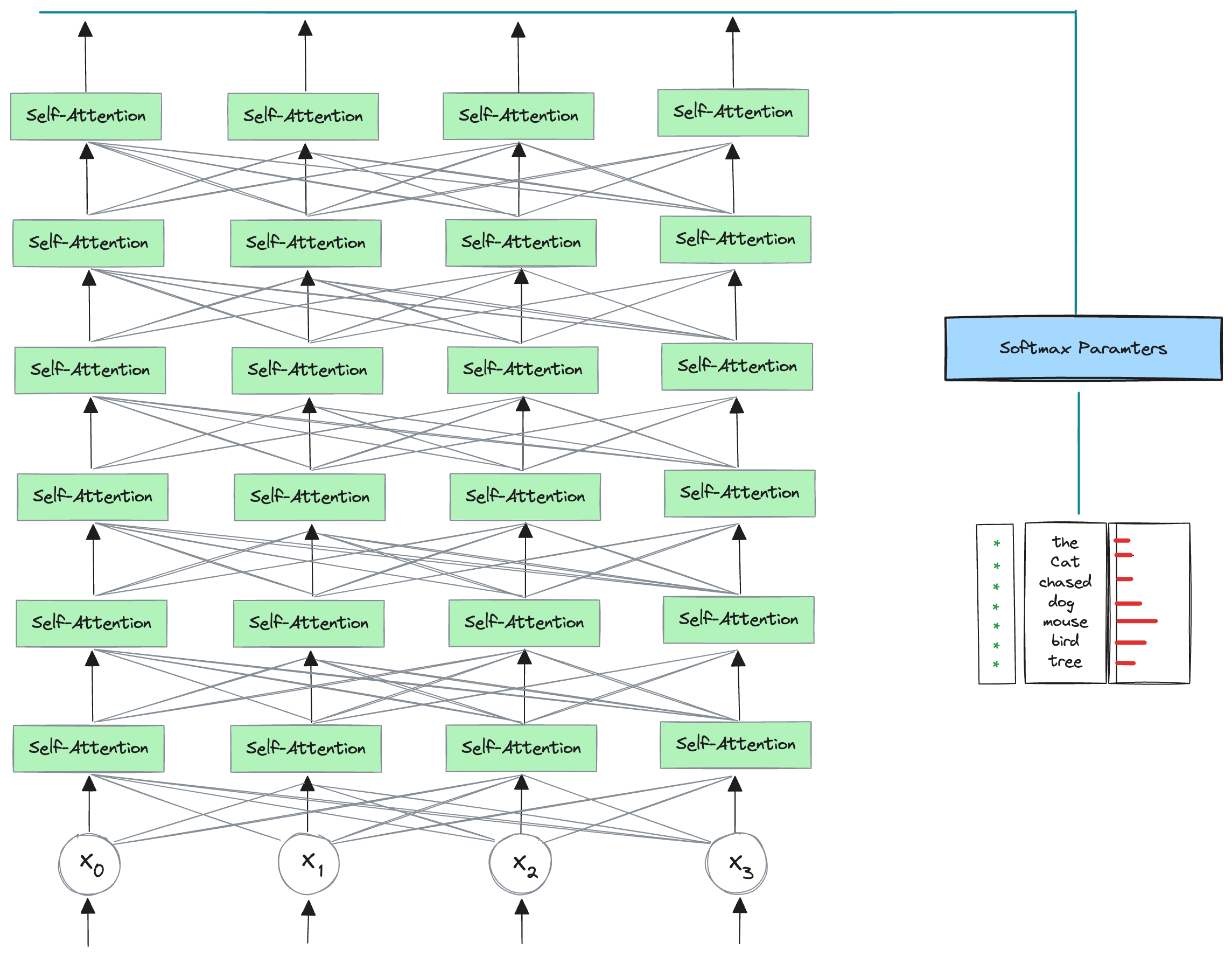
The more layers we have, the deeper the understanding—some models boast 24 layers or more!
From Noncontextual to Contextual
The beauty of transformers is their ability to turn noncontextual embeddings (think of these as raw, unprocessed thoughts) into contextual embeddings (fully formed ideas that take into account the surrounding words).
By the time an embedding reaches the top of our metaphorical stack, it has a comprehensive understanding of the entire sentence. We can get any contextual embeddings output and perform the language modelling.
Constructing a Language Model with Transformers
But how do we transform this understanding into a language model? It’s simpler than it seems. We take one of the contextual embeddings—typically the first one from the transformer—and use it as a foundation. From here, we apply a linear transformation, similar to what we’ve done with Word2vec and RNNs, to map this embedding to scores for every word in our dictionary.
The Flip Side of Transformers
No technology is without its drawbacks, and transformers are no exception. They’re computationally intensive and require significant hardware capabilities to run efficiently, especially if we’re not using specialized hardware like TPUs. They also need a predetermined number of tokens, typically capped at 512. This means any sentence longer must be cut short, and any shorter must be filled out, like adjusting a one-size-fits-all garment.
Conclusion:
In conclusion, while we’ve covered a lot of ground, there’s still much more to the story of transformers. They are complex, powerful, and a bit demanding, but the results they yield are nothing short of impressive. Stay tuned for the next installment where we’ll continue our exploration into the innovative world of transformers and how they’re shaping the future of NLP.

And there you have it, another step deeper into the fascinating world of language models. Remember, this is an ongoing conversation, so keep an eye out for our next piece where we’ll pick up right where we left off. See you then!
Reference
- Transfer learning and Transformer models (ML Tech Talks) 2.Vaswani, Ashish, et al. “Attention Is All You Need” arXiv preprint arXiv:1706.03762 (2017)1.
- A (relatively) simple guide to language models
- Language Models, Explained: How GPT and Other Models Work
- An Introduction to Using Transformers and Hugging Face





{kind=link}