
Hello to all data enthusiasts out there!
Ever wondered how banks or lending institutions decide whom to give a loan? Or why sometimes, even with a seemingly good credit score, some people are denied credit? Well, one of the crucial aspects that these institutions consider is the risk of loan default. Predicting loan defaults is an ongoing challenge in the financial world. As part of Coursera’s Data Science Coding Challenge, I embarked on a journey to tackle this very issue.
The Problem:
The task was to build a predictive model using a dataset that contained various borrower-specific features, such as their income, credit score, employment duration, and more. The goal? Predict if they would default on their loan.
My Achievement:
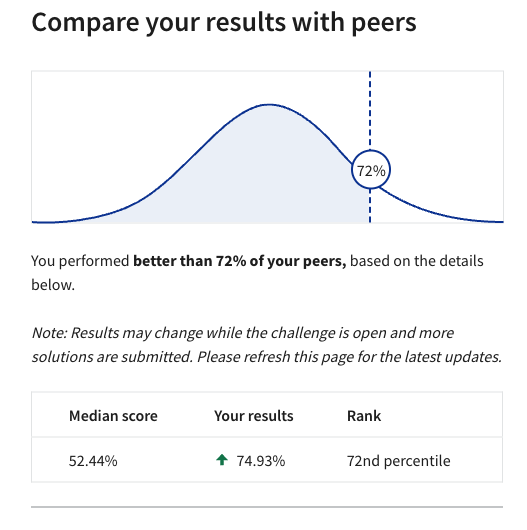
I’m elated to share that my solution ranked in the top 30% of all submissions. A considerable achievement given the complexity and competition!
Getting Started: The Exploratory Phase
Before even thinking about modeling, I knew I had to get intimately familiar with the data. And so began my exploratory data analysis (EDA) adventure.
Distribution Insights:
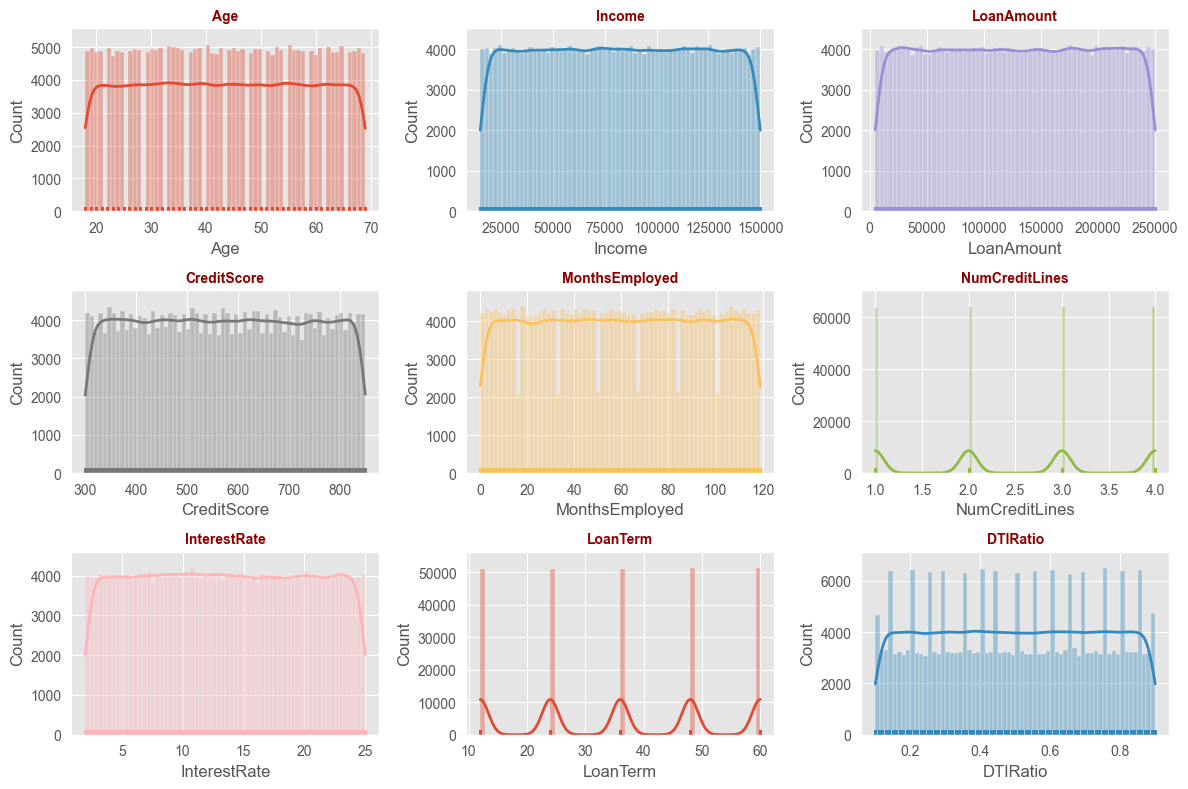
One of the first things I noticed was how the distribution of certain features varied significantly. For instance, the majority of borrowers had credit scores in a specific range, but there were significant outliers.
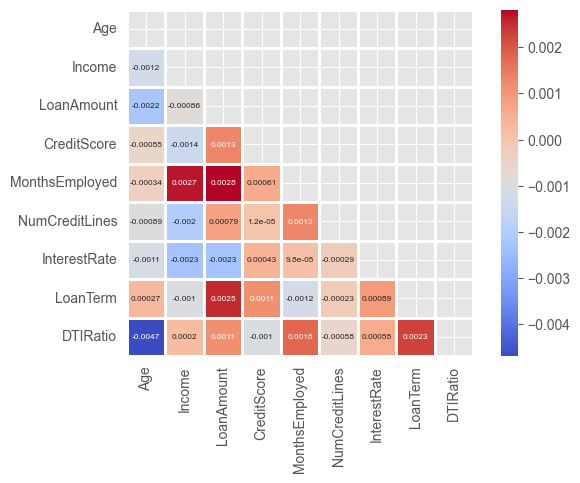
Correlations Unearthed:
I delved into understanding how various features related to one another. This was eye-opening! Some features had strong correlations, guiding me towards potential multicollinearity issues during modeling.
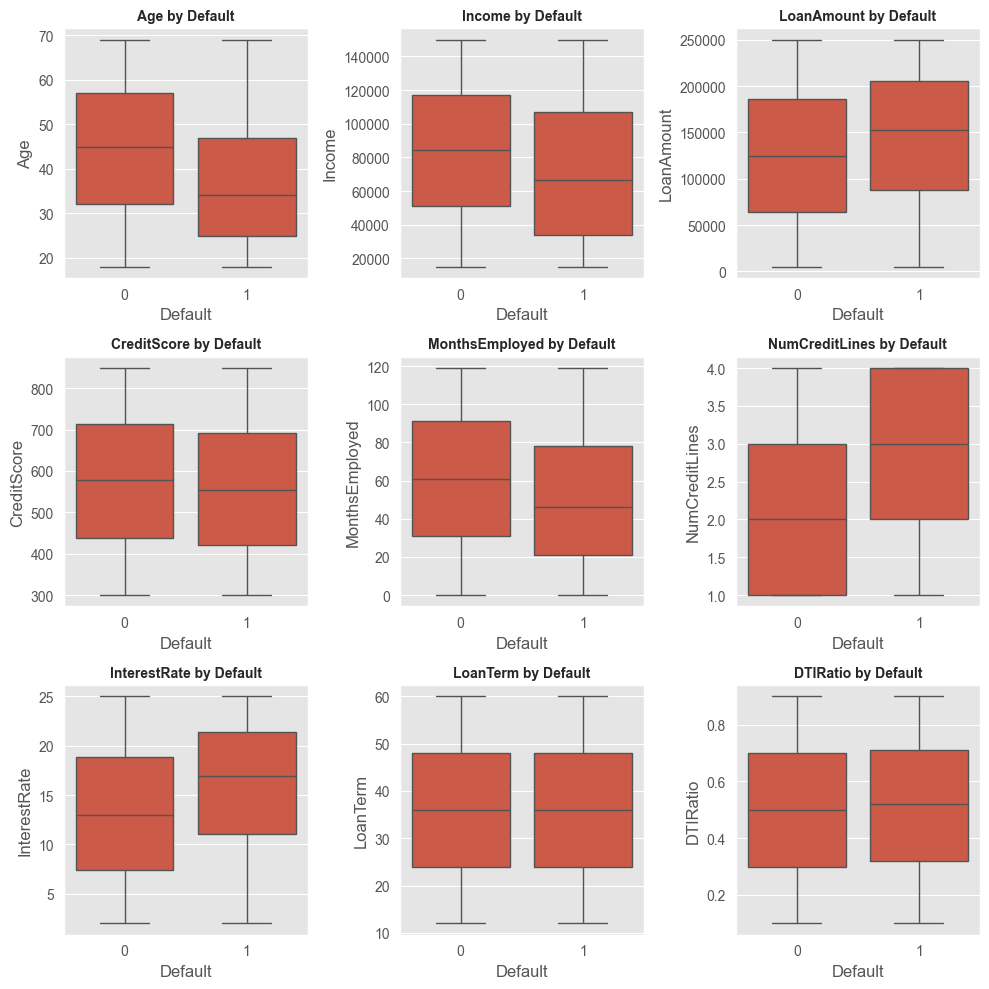
Categorical Analysis:
Analyzing categorical variables, like employment type and education, unveiled some biases in loan allocation. Certain categories had higher incidences of defaults, a crucial piece of info!
These EDA insights were invaluable! They didn’t just inform my preprocessing strategies but also gave me an intuitive understanding of potential pitfalls and avenues to explore.
Crafting the Data Pipeline
Post-EDA, I ventured into preprocessing the data. This involved:
- Feature Selection: Based on the insights from EDA, I shortlisted the most relevant features.
- Data Cleaning: This step was all about ensuring data integrity. I removed duplicates and dealt with missing values.
- Data Transformation & Scaling: I normalized certain features and used one-hot encoding for categorical variables.
- Handling Class Imbalance: With the help of SMOTE, I addressed the imbalance in the dataset. This ensured that my model would be trained on a more balanced representation of defaults and non-defaults.
Models, Models Everywhere!
After prepping the data, the real fun began – modeling! I experimented with a slew of models, including logistic regression, random forests, XGBoost, CatBoost, KNN, and Gaussian Naive Bayes. I utilized a comprehensive search space for hyperparameters, tweaking and tuning to extract the maximum performance.
The GitHub Repository
I’ve meticulously documented my entire journey and the code on GitHub. For those curious to dive deeper, here’s the link to the repository.
Final Thoughts:
The Coursera Data Science Coding Challenge was a roller-coaster of learning and excitement. It reinforced the importance of a methodical approach – starting with understanding the data, meticulously preprocessing it, and then experimenting with models.





{kind=link}