
If you’re curious about the intricacies of Natural Language Processing (NLP), how we encode text for NLP tasks, Don’t miss out on enriching your understanding of NLP — follow this link to catch up on the conversation.
What is the task of language modeling?
The task of language modeling involves predicting the next word (nth word) in a sentence, given the preceding words (0 to n-1). This prediction task allows us to capture patterns and structures within the text.
Language modeling can be explained in terms of probability, specifically the probability of predicting the next word given the context of the previous words in a sentence. The goal is to estimate the conditional probability distribution of the next word, given the history of words in the sentence.
Suppose we have a sentence: “The cat is __.”
To perform language modeling, we want to predict the most probable word to fill in the blank based on the context provided by the previous words. In this case, the context is “The cat is.”
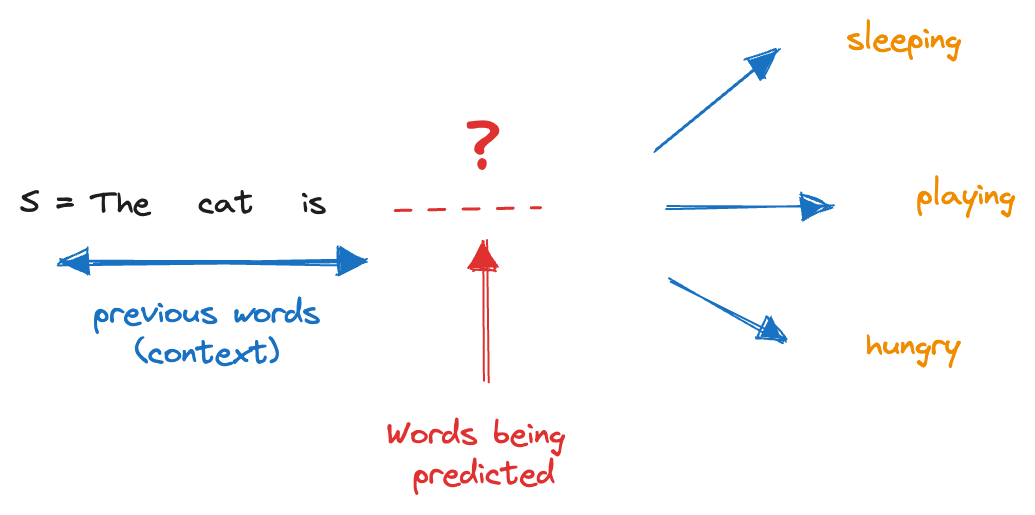
To estimate the conditional probability of different candidate words given this context, we rely on a language model trained on a large corpus of text. The model analyzes the frequency and co-occurrence of words to learn the probabilities.
For instance, the model may estimate the following conditional probabilities:
P("sleeping" | "The cat is")
P("playing" | "The cat is")
P("hungry" | "The cat is")
Based on the learned probabilities, the language model can predict the most likely word to complete the sentence.
If "sleeping" has a higher probability compared to the other words, the model would predict "The cat is sleeping" as the most probable completion.
By leveraging probability estimation, language modeling enables us to predict the next word in a sentence based on the preceding context. This fundamental approach forms the basis for various natural language processing tasks and applications.
Evolution of Language Models
Language modeling has undergone significant advancements over the years, with notable milestones such as Word2Vec, Recurring Neural Networks (RNNs), and Transformers. In this section, we’ll explore the details, advantages, and challenges associated with each approach, tracing the progress in language modeling.
Word2Vec
Word2Vec, introduced in 2013, revolutionized language modeling by introducing distributed representations for words. It enabled the encoding of semantic relationships and similarities between words through embeddings.
Here’s an example to illustrate the Word2Vec-based language model:
Consider the sentence: “The cat chased the __.”
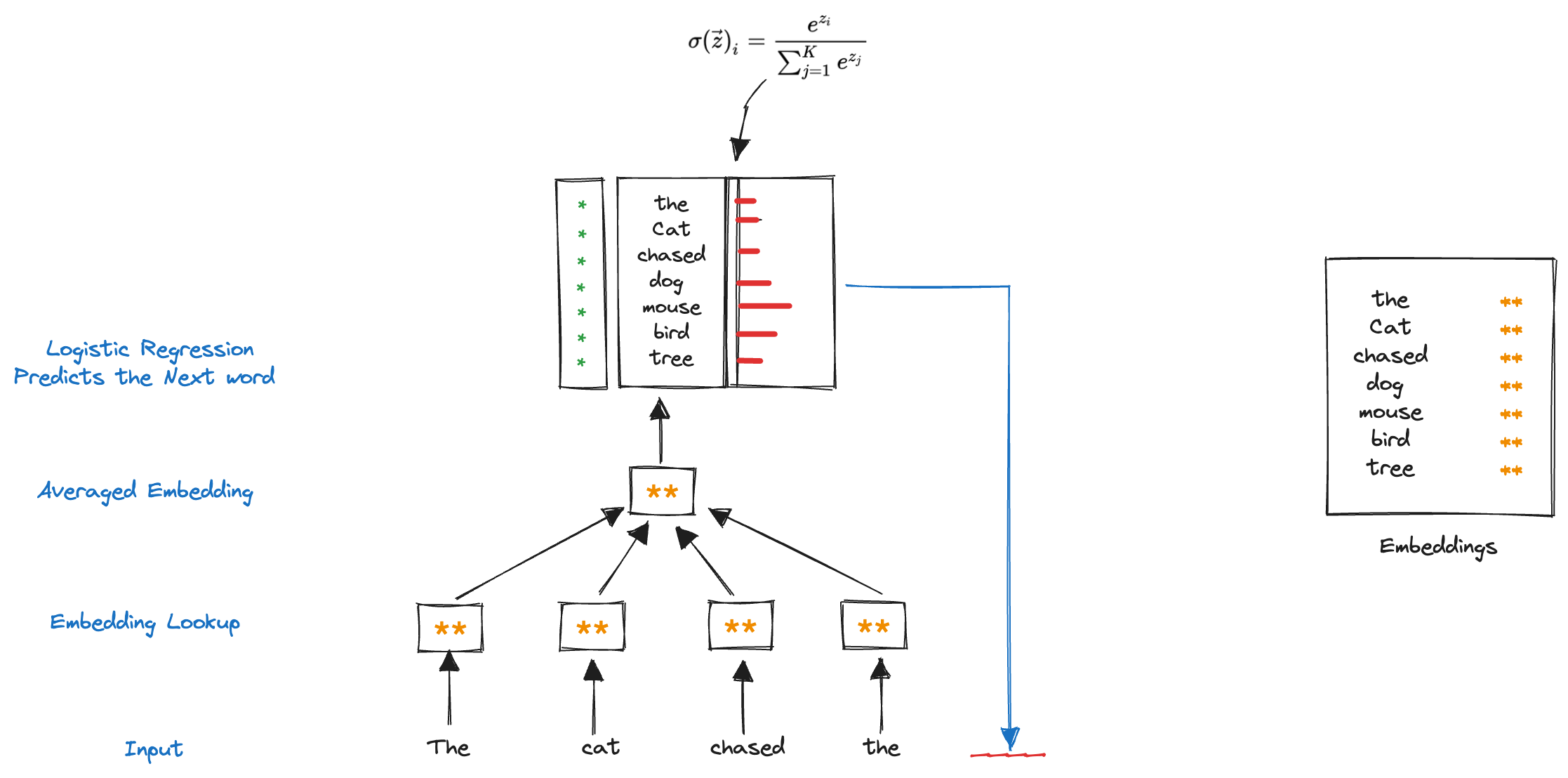
In this example, we want to predict the missing word based on the context provided by the previous words. Let’s assume the vocabulary consists of four tokens: “mouse,” “bird,” “dog,” and “tree.”
Using Word2Vec-inspired language modeling, the model starts with randomly initialized embeddings for each token in the dictionary.
Next, the embeddings for the context words (“The,” “cat,” and “chased”) are looked up in the token-embedding matrix, resulting in four two-dimensional vectors.
To generate a prediction for the missing word, the embeddings are aggregated. In this simplified model, the embeddings can be averaged together.
The averaged embeddings are then transformed using a linear transformation, mapping them to a seven-dimensional vector representing the vocabulary size. The softmax parameters are involved in this transformation.

The model assigns arbitrary weights and scores to the vocabulary tokens based on the transformed embeddings.
To produce a probability distribution, the scores are normalized using logistic regression, ensuring that the probabilities of all tokens sum up to 1.
For instance, if the model assigns higher probabilities to “mouse” and “bird” compared to “dog” and “tree,” it indicates a stronger likelihood that the missing word is either “mouse” or “bird.”
The model’s prediction is evaluated by comparing its probability distribution to the true distribution, which assigns a probability of 1 to the correct missing word and 0 to all other words.
By calculating the cross-entropy between these two distributions, the model’s error is determined, and through backpropagation, the model can adjust its weights to improve future predictions.
Disadvantages
- Limited Word Disambiguation
- One of the main drawbacks of Word2Vec is its limited ability to disambiguate words with multiple meanings.
- The model associates a single fixed embedding with a word, regardless of its context.
- This limitation can lead to incorrect interpretations in certain cases.
- For example, consider the word “bat.” Word2Vec would assign the same embedding to “bat” in the context of a sports game (e.g., baseball bat) and a nocturnal mammal (e.g., bat flying in the night).
- Contextual Variations
- Word2Vec does not capture contextual variations in word meaning.
- It treats words as isolated entities, neglecting the impact of neighboring words.
- For instance, in the sentence “I saw a bat,” the word “bat” can refer to either the animal or the sports equipment. However, Word2Vec would assign the same embedding to both occurrences, failing to differentiate based on the contextual differences.
- Homonym Confusion
- Word2Vec struggles with distinguishing between homonyms, which are words with the same spelling but different meanings. Since it assigns a single embedding to a word, homonyms end up with identical representations.
- For example, Consider the sentence: “I saw a bat flying in the __.” we want to predict the missing word based on the context provided by the previous words. Let’s assume the vocabulary includes two homonyms: “sky” and “cave.”
- Using Word2Vec, the model assigns a single embedding to the word “bat” regardless of its context. As a result, both meanings of “bat” (referring to the animal or a wooden implement for hitting a ball) are represented by the same embedding.
- When predicting the missing word, the model may assign probabilities to “sky” and “cave” based on the context, but due to the limitation of Word2Vec, the probabilities for both options may be similar.
- Word2Vec would map both meanings to the same embedding, potentially leading to ambiguous interpretations.
- Polysemous Words
- Polysemous words, which have multiple related meanings, pose a challenge for Word2Vec. The model fails to capture the nuanced variations in meaning based on context.
- For instance, the word “run” can refer to physical activity or operating a machine.
- Word2Vec would assign a single embedding to “run,” ignoring the context-specific distinctions between the two meanings.
Recurrent Neural Networks (RNNs) surpass the limitations of Word2Vec by contextualizing word embeddings, allowing for better disambiguation and capturing long-term dependencies. Their ability to encode sequential information and incorporate surrounding context makes RNNs a more powerful tool for accurate language modeling.
Recurrent Neural Networks (RNNs) in Language Modeling
In the realm of language modeling, Recurrent Neural Networks (RNNs) provide a powerful mechanism for contextualizing word embeddings and disambiguating words based on their context. In this section, we’ll delve into the workings of RNNs and their role in language modeling, including advantages and disadvantages.
How it works ?
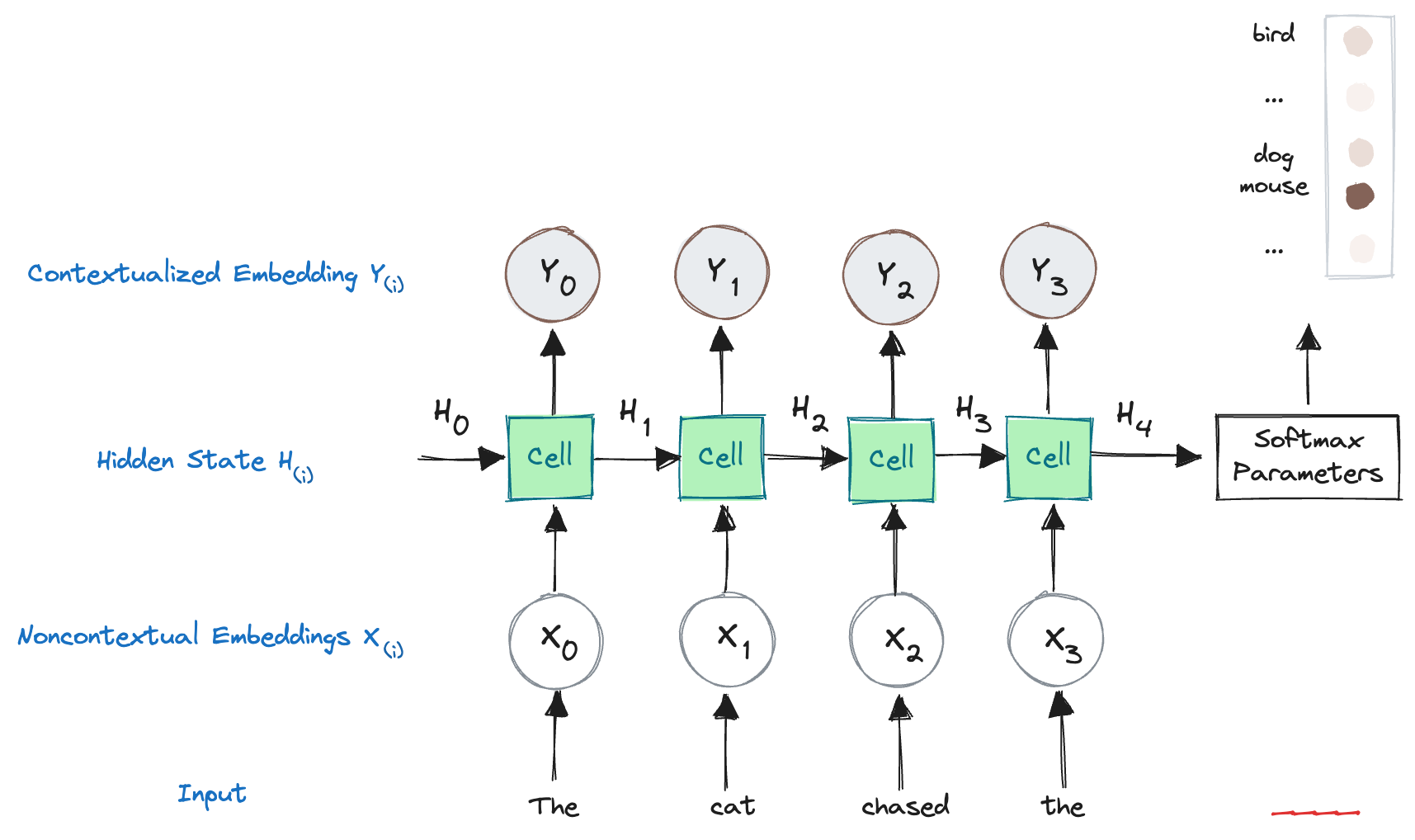
- In language modeling with RNNs, we start with noncontextual embeddings, such as those obtained from models like Word2Vec. These embeddings represent individual words in a fixed-dimensional vector space.
- RNNs process words in a sequential manner, taking into account the order in which they appear in the sentence. Each word is fed into the RNN cell one at a time.
- The RNN cell has an internal state, denoted as “H” in the image. This internal state is continuously updated as the RNN progresses through the sentence. It serves as an encoding of the left-hand side context of the sentence encountered so far.
- The RNN cell combines the internal state “H” with the noncontextual embedding of the current token (X) to produce a contextualized embedding, denoted as “Y.” This contextualized embedding captures the influence of the preceding context on the current word.
- The contextualized embedding helps disambiguate words based on context and predict the next word. For example, with “The cat chased the,” the RNN may predict “mouse” as the likely next word.
- The RNN is trained using cross-entropy loss, adjusting its weights to improve predictions over time.
Disadvantages
RNNs have been widely used for language modeling due to their ability to contextualize word embeddings and capture dependencies in sequential data. However, despite their advantages, RNNs also come with certain disadvantages that hinder their performance in certain scenarios. In this section, we will explore the drawbacks of using RNNs for language modeling and understand how they impact the model’s efficiency and accuracy.
- Slow Sequential Processing:
- One of the main disadvantages of RNNs is their inherent sequential processing nature. As RNNs process words one after another, each word’s embedding depends on the embeddings of all previous words in the sentence. Consequently, the model needs to wait for the computation of preceding embeddings, resulting in a time complexity of O(N) with respect to the number of tokens in the sentence. This sequential dependency makes RNNs relatively slow, especially for long sentences or texts.
- Consider a lengthy paragraph with several sentences. Since RNNs process the entire paragraph sequentially, the model may encounter delays in predicting the last few words of each sentence, as it must first process all the preceding words.
- Vanishing Gradient Problem:
- The vanishing gradient problem is another drawback of RNNs. As the network propagates back through time during training, gradients may become extremely small, leading to challenges in learning from earlier tokens. In lengthy sentences or texts, the influence of early words on later predictions diminishes significantly, resulting in a reduced capacity to capture long-term dependencies in language.
- In a complex sentence like “After studying all night, John finally understood the concept,” the word “studying” might have a significant impact on understanding “concept.” However, due to the vanishing gradient problem, the RNN might fail to capture the contextual relationship between the two words effectively.
- Unidirectional Processing:
- Many RNN architectures are unidirectional, processing text from left to right. This unidirectional approach might lead to limitations when relevant context lies to the right of the current word. As a result, the model may struggle to make accurate predictions based on information beyond its left-hand context.
- For a sentence like “The cat chased the mouse,” an RNN processing from left to right would already encounter “mouse” before “chased.” As a result, the model may not have the full context required to accurately disambiguate the word “chased” as the past tense of the verb.
Transformers in language modeling
Transformers represent a groundbreaking advancement in language modeling and currently stand as the state-of-the-art technique. Unlike traditional unidirectional models, Transformers excel at considering contextual information from both the left-hand side and the right-hand side of the sentence. This bidirectional processing empowers the model to understand the nuances of language and overcome the limitations faced by previous approaches.
In the upcoming blog post, we will delve into the fascinating world of Transformer models and explore how they revolutionized language modeling. We will dive deep into the workings of Transformers, understand their attention mechanisms, and witness how they overcome the limitations of traditional models. So stay tuned for an exciting journey into the realm of Transformers and their impact on advancing natural language processing!
Conclusion:
Language modeling has witnessed significant progress through various techniques, including Word2Vec, RNNs, and the cutting-edge Transformers. While Word2Vec introduced distributed word representations, RNNs contextualized embeddings to capture dependencies. However, both approaches faced challenges with speed, vanishing gradients, and unidirectional processing. In contrast, Transformers emerged as a revolutionary solution, embracing bidirectional context and capturing long-range dependencies more effectively. With their remarkable ability to handle sequential data, Transformers have opened up new possibilities in natural language processing and become the preferred choice for language modeling. As researchers continue to push the boundaries of language models, the journey towards achieving even more accurate and contextually rich language understanding is poised to continue.




{kind=link}