
What is Natural Language Processing (NLP)?

NLP aims to enable computers to understand, interpret, and generate human language, opening up a lot of possibilities. The process starts with an input text, which is analyzed by the NLP model to generate an output. The output can include predictions, text summaries, speech, information extraction, translation, and more. NLP enables computers to understand and generate human language, opening up various applications and tasks in natural language processing.
- machine translation
- sentiment analysis
- text summarization
- speech recognition
- chatbots
- information extraction, among others.
Encoding text in NLP
Encoding is an essential step in natural language processing (NLP) as it allows us to represent text data in a format that can be processed by machine learning models. There are various techniques to encode text in NLP models. Some commonly used encoding methods include:
- Word Dictionary Encoding
Word Dictionary Encoding involves assigning a unique integer index to each word in a corpus. Each word is represented by its corresponding index. Say we have a corpus of 3 words. Here’s an example of Word Dictionary encoding:- Word: “apple”, Dictionary Index: 1
- Word: “orange”, Dictionary Index: 2
- One-Hot Encoding
One-Hot Encoding represents each word as a binary vector where all elements are zero except for the index corresponding to the word’s position in the vocabulary, which is set to one. Here’s an example of One-Hot encoding:- Word: “apple”, One-Hot Vector: [0, 1, 0]
- Word: “orange”, One-Hot Vector: [0, 0, 1]
Here’s an example of a dictionary with 10 words and their corresponding index, along with the one-hot encoding representation:
| Word | Index | One-Hot Encoding |
|---|---|---|
| dog | 0 | [1, 0, 0] |
| apple | 1 | [0, 1, 0] |
| orange | 2 | [0, 0, 1] |
Problem with the One-Hot Encoding
- High dimensionality
- One-hot encoding requires a vector with a dimension for every entry in the vocabulary.
- As the vocabulary grows larger, the dimensionality of the one-hot vectors also increases. For example, if the vocabulary has 100,000 entries, each one-hot vector would be a 100,000-dimensional vector.
- This can lead to very high-dimensional vectors, especially when dealing with large vocabularies. This high dimensionality can cause computational inefficiency and memory overhead.
- Lack of semantic information
- One-hot encoding fails to capture any semantic or contextual information about the tokens. Each token is represented as a discrete and isolated vector with no inherent relationship or similarity to other tokens. This means that words with similar meanings or associations will have vectors with no similarity in their representation.
- let’s assume we want to capture the semantic relationship between “apple” and “orange” using one-hot encoding. However, since one-hot vectors represent tokens as isolated and discrete vectors, the vectors for “apple” and “orange” would be orthogonal (perpendicular) to each other:
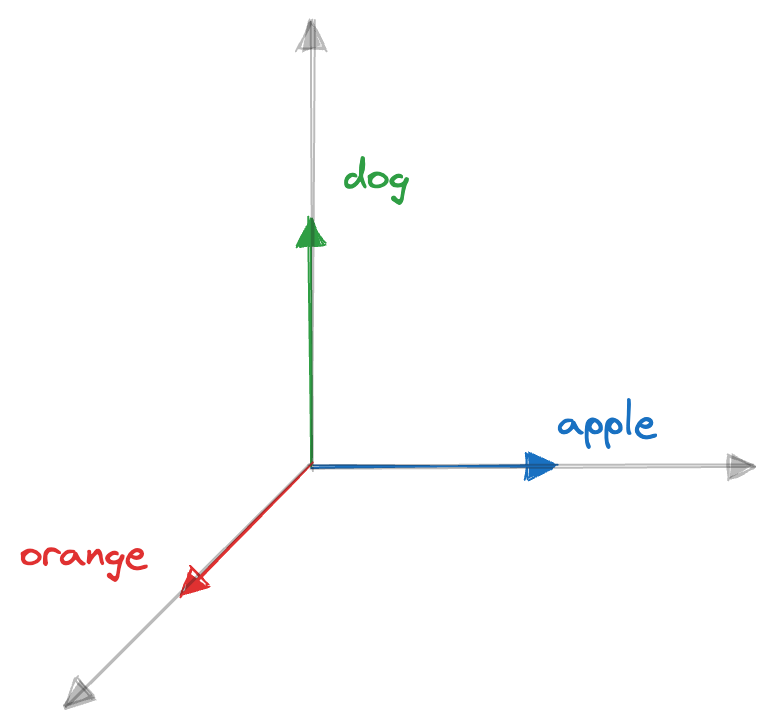
-
It can be addressed using continuous vector representations. Here’s an example illustrating how continuous vector representations can overcome these limitations: “apple”: [1.5, 0.9, 1.4], “orange”: [0.9, 0.1, 0.8] , “dog”: [0.3, 0.2, 0.7]
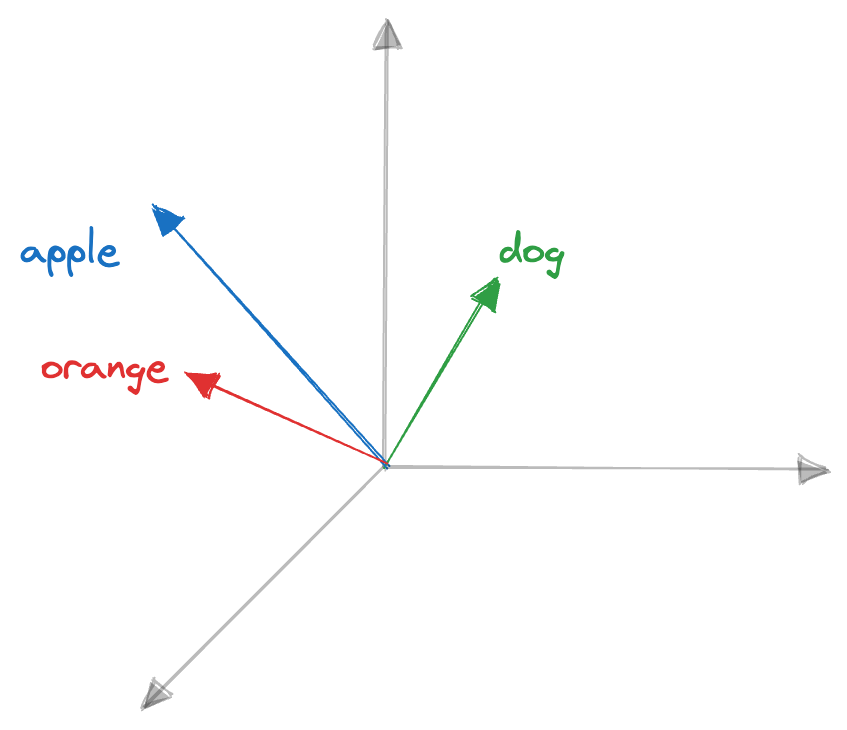
- With continuous vectors, we can encode semantic information. For example, in the given vectors, “apple” and “orange” have vectors that are closer in the vector space compared to “dog.” This closeness reflects the semantic similarity between “apple” and “orange” as both being fruits, while “dog” is an Animal.
- Continuous vector representations can have a lower dimensionality compared to one-hot encoding. This way of embedding tokens is known as continuous,or distributed embedding.
Capturing World Knowledge
- Word embeddings should encompass world knowledge by reflecting properties like gender or part of speech or sentiment etc. Various dimensions of the embedding vector can be dedicated to different aspects. For example,

- the first three dimensions could encode gender, and the next three dimensions could encode part of speech. This allocation of dimensions is a hypothetical example, and the model is expected to discover meaningful relationships within the vector space.
Relative vector distance
-
The mechanism employed to express desired relationships in word embeddings is relative vector distance. By manipulating the distances between word vectors, we can capture specific relationships. Let’s consider a couple of examples: First, we define a loss function that quantifies the discrepancy between the predicted output and the target output. In binary classification, a commonly used loss function is the binary cross-entropy loss:
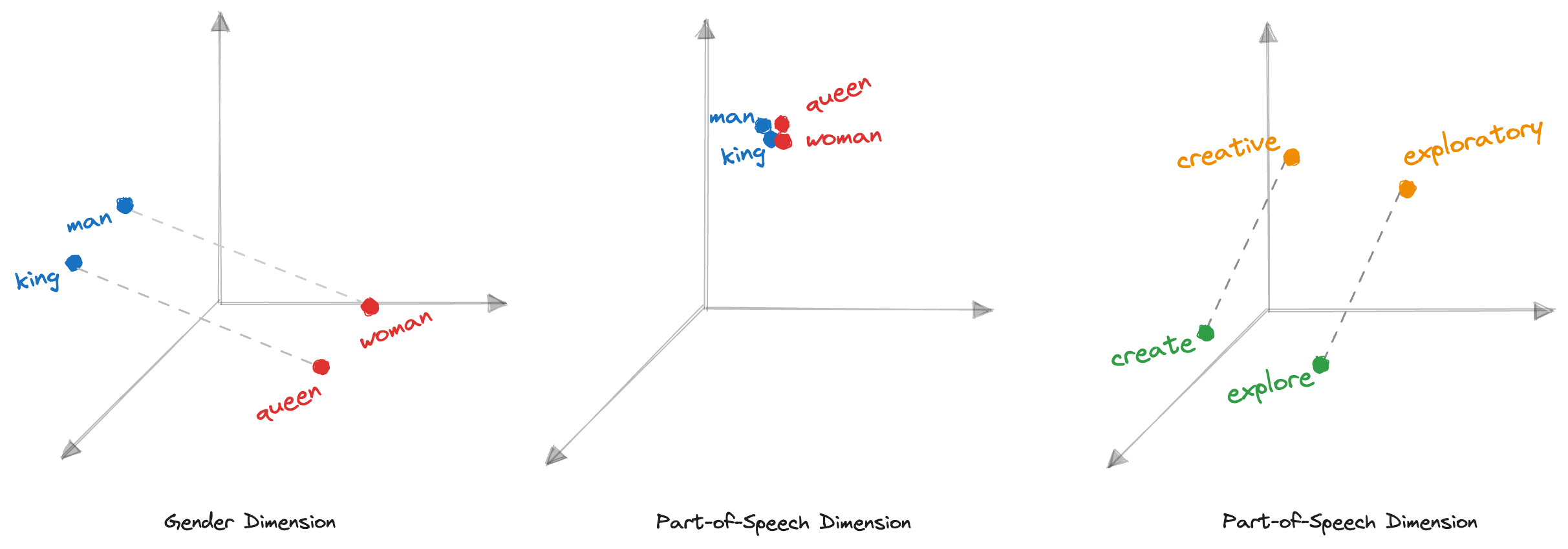
- On the gender dimension, the vectors for “king” and “queen” should be as far apart as the vectors for “men” and “women.” This reflects the relationship between genders and ensures that gender-related associations are captured within the embeddings.
- On the part-of-speech dimension, words like “king,” “queen,” “man,” “woman,” and other nouns should be clustered together at a distance close to zero. Since they all belong to the same part of speech, this clustering ensures that the embeddings capture the commonality among nouns.
- Word embeddings might capture semantic relationships between words. For example, verb-adjective pairs like “create” and “creative” should exhibit a similar distance in the vector space as related words like “explore” and “exploratory.” This enables models to understand and leverage the connections between different parts of speech.
Learning Useful Word Embeddings:
- In the realm of natural language processing, one of the key challenges is learning meaningful word embeddings. These embeddings capture the contextual relationships between words and enable machines to understand and process language. Fortunately, the vast amount of freely available text on the internet, particularly from sources like Wikipedia, offers a valuable resource for training language models.
- Wikipedia, with its extensive collection of articles in multiple languages, provides a controlled and reliable source of information. By examining related pages, such as “king” and “queen,” we can observe commonalities and shared words like “monarch.” Extracting word knowledge from these pages becomes an exciting possibility.
Gamifying Text with Supervised Tasks:
- Transforming unsupervised text data into a supervised task is a common practice in machine learning.
- In this context, we can prompt the model to predict the next word in a sentence.
- For example, given the context “king is the title given to a male,” the model generates a probability distribution over the vocabulary, indicating the most likely words to follow. Through this process, the model learns to associate words and make predictions based on contextual cues.
Conclusion:
In the quest for effective word embeddings, leveraging the wealth of text available on the internet, particularly from sources like Wikipedia, is a promising approach. By gamifying text through supervised tasks, language models can extract knowledge from this vast corpus and learn meaningful embeddings. These embeddings, in turn, enhance machines’ understanding of language and empower them to perform a wide range of natural language processing tasks.
Word embeddings are essential building blocks in the field of natural language processing, facilitating advancements in machine understanding and communication.
In the Next Blog I will be covering more on Language Modeling & Understanding its Basics



%20and%20Word%20Embeddings){kind=link}